

How Does Deep Learning Work?
A comprehensive overview of deep learning, exploring how neural networks learn from data, the architecture behind modern AI systems, and why deep learning has become the backbone of artificial intelligence.

Per Näslund
I will try to give you a quite simple explanation of what actually goes on in a deep learning model that could be read by anybody, no matter previous knowledge. Some things are a bit simplified in order to accommodate that.
Let’s begin with sorting some terms out. Deep learning is a sub-field within the wider machine learning field. Machine learning is sometimes used when building AI software. AI is however a very broad concept which also involves NPCs in games, such as those little ghosts that try to get you in Pacman. Those ghosts does not have any machine- or deep learning behind their intelligence however.

The goal when doing deep learning is to provide a correct output given a certain input. Such <input | output>-pairs could in the case of self driving cars be: <photo from on-car camera | "Pedestrian in front of you"-signal> or in the case of someone building a stock trading bot be <press-release | buy-signal>.

Let’s do our example on text translation, which is actually done with the help of deep learning in Google Translate. In this case, we want to translate sentences from English to Swedish. The first problem we need to solve is that a deep learning model wants its input converted to a numerical representation. Let’s use this ASCII-table to translate the English letters to numbers before we run it through the deep learning model.
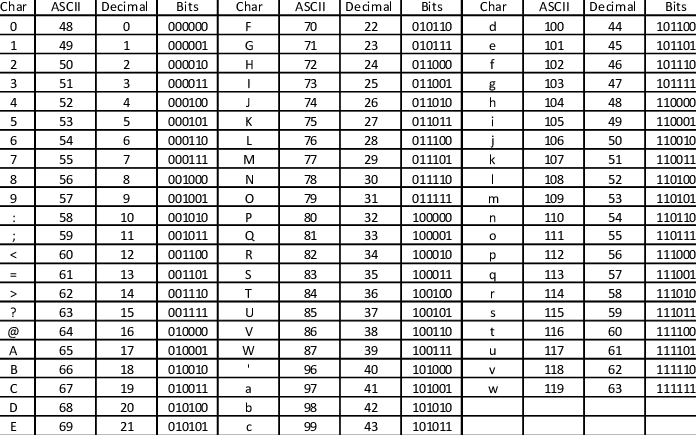
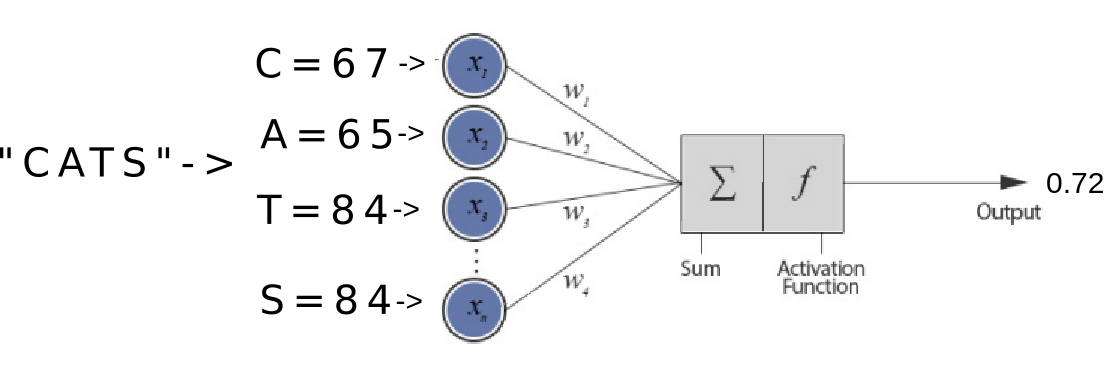
Nice, now let’s send the numbers into what is called a neural network. The neural network consists of something called perceptrons. These perceptrons take many inputs, and each input (seen as x’s in the image below) is multiplied by a weight (seen as w’s in the image). The sum of the results of all these multiplications are run through a quite simple mathematical function called the activation function and a number comes out on the other side.
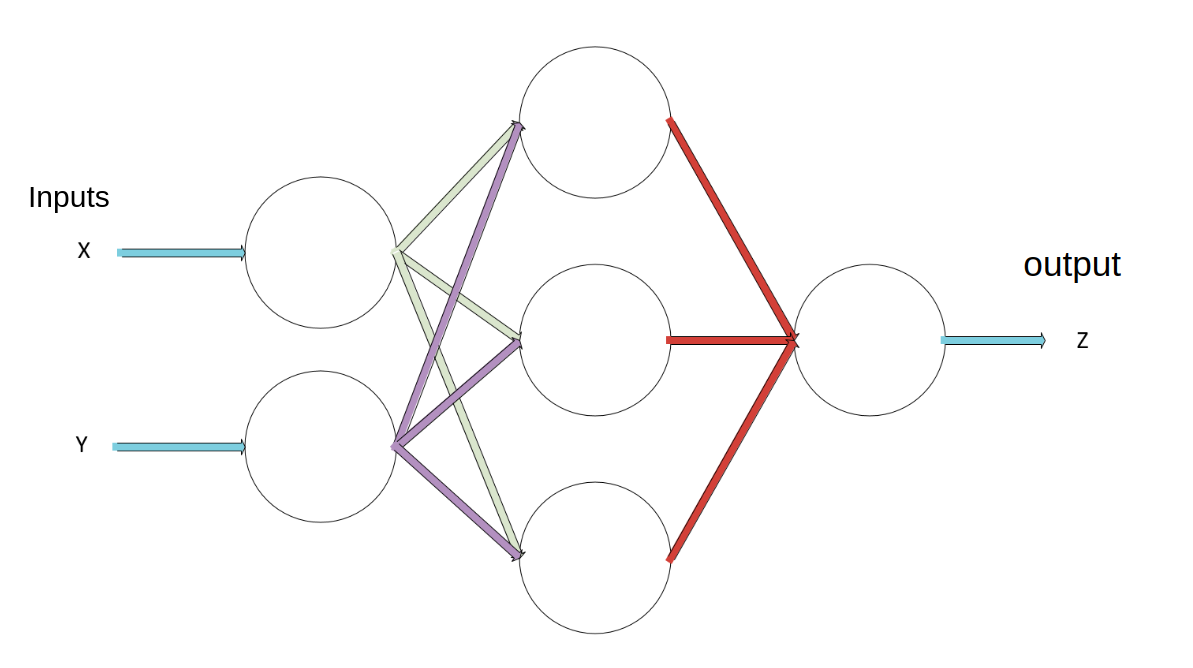
If you put several of these perceptrons in a net you get the actual artificial neural network. The more layers of perceptrons in a network, the “deeper” it is. And hence the term DEEP learning!
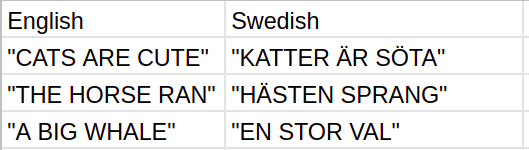
Alright, now it is time to train this model so that it does what we want it to do, translating sentences from English into Swedish. For that we also need a training dataset that holds English sentences and their Swedish translations:
Let’s set those weights (W1-W6 below) to some random numbers and see what happens when we run the sentence “CATS ARE CUTE” through the model:
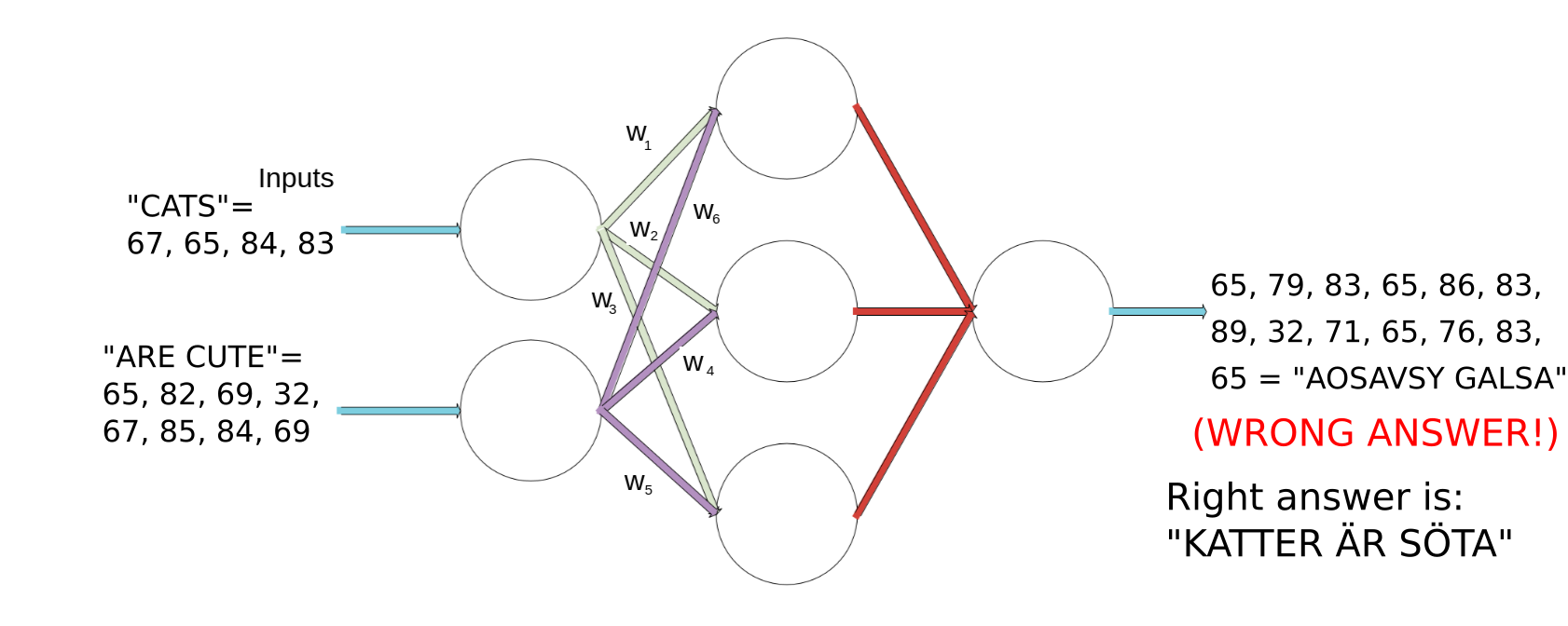
Oops, that didn’t turn out very well. Let’s try to change the weights to some other random numbers and run it again:
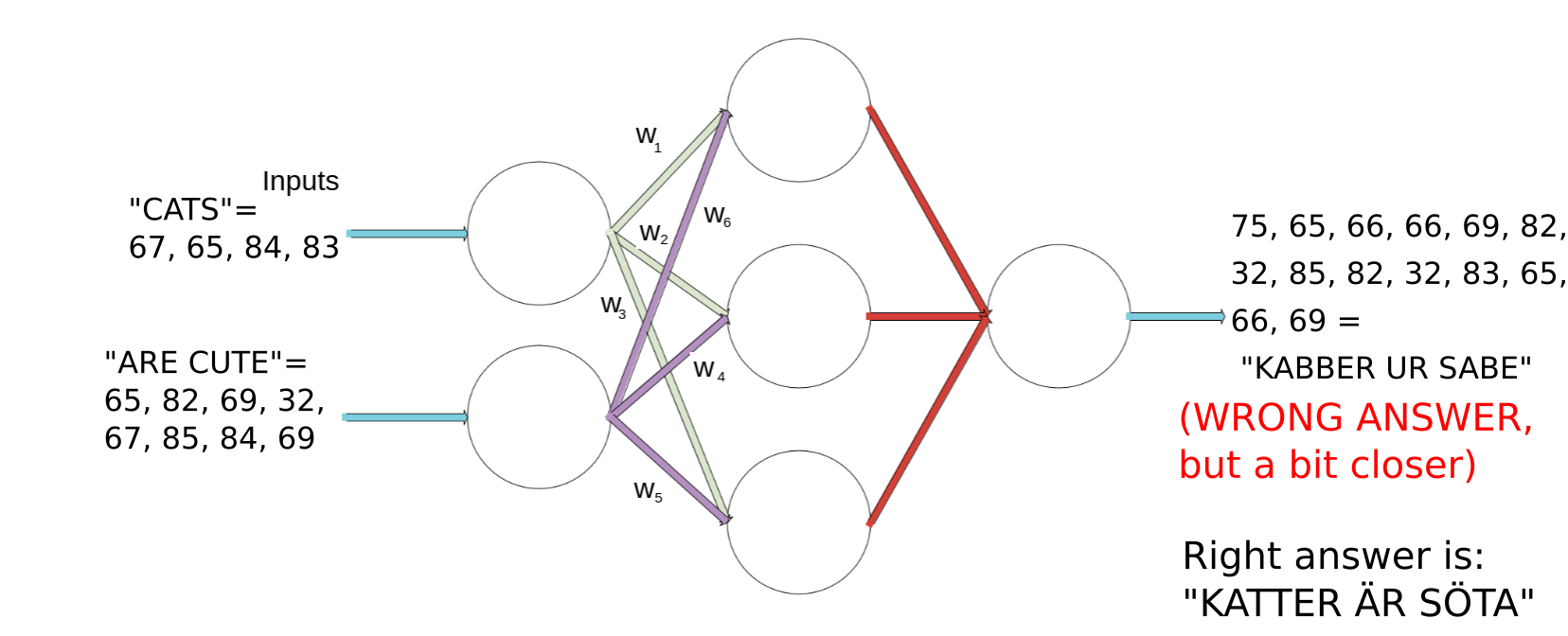
Look! This time i was a bit closer to the answer. Let’s keep changing the numbers in that same “direction”, meaning that if we changed the weight W1 from 0.3 to 0.4, then maybe we should try to set it to 0.5 and see what happens.

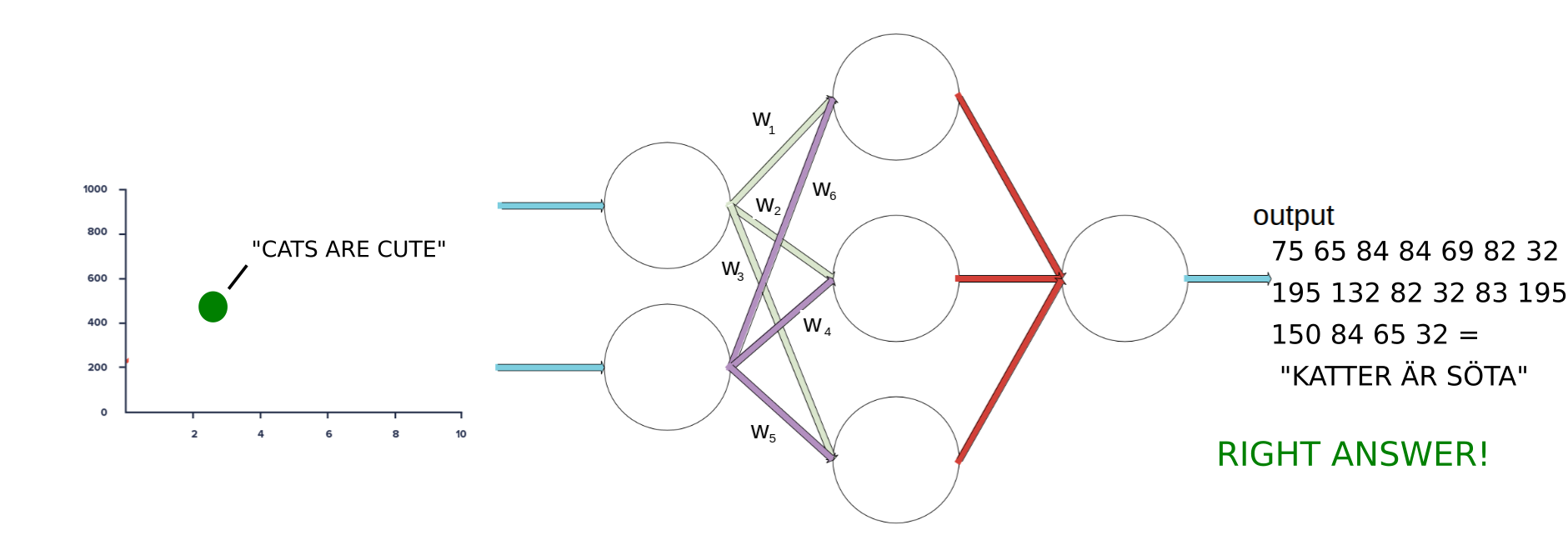
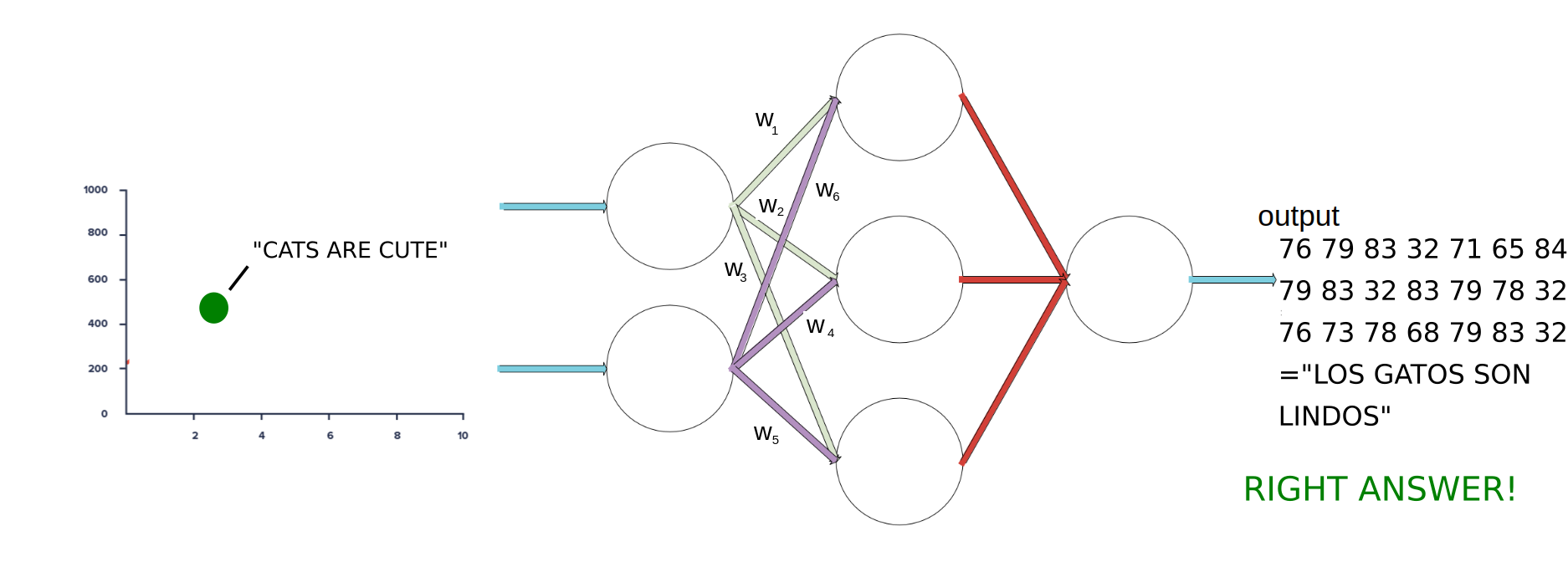
IT WORKED! We got the right answer! Now this usually takes thousands of iterations doing this on thousands data points and changing the weights in a network with more layers and perceptrons. But I hope it conveyed the gist of it.
The next step is to test our newly trained model on sentence-pairs that it hasn’t seen before (a test set). That’s how you know if it actually works in real life or just on the data you trained on (overfitting). If that all works out, we can deploy it to our translation website!
Now I haven’t been completely honest with you. Translation is usually done using two models. But keep reading because this is where it gets really interesting! You normally have one “encoder model” and one “decoder model”. You encode the input sentence into an intermediate representation of the actual meaning of the sentence. You can think of the intermediate representation like one or many dots in one of those Excel dot charts…
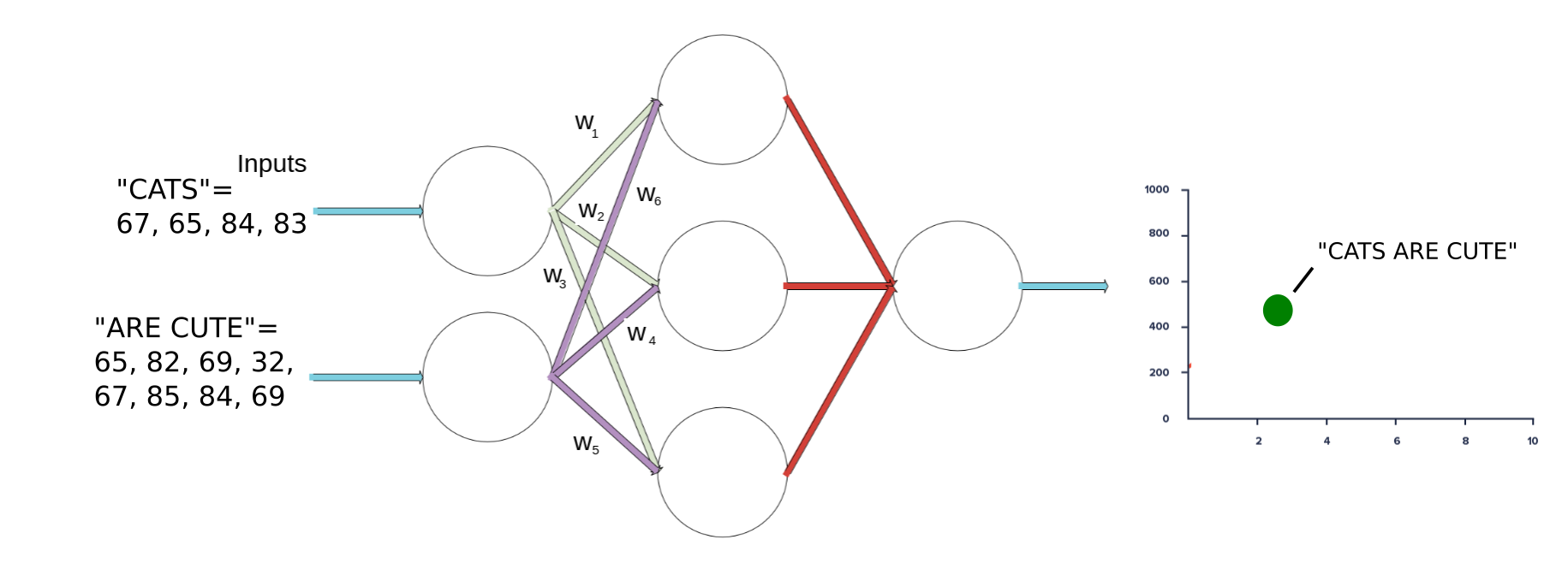
…or maybe not exactly. This chart actually has HUNDREDS of dimensions instead of just two like in Excel! That leads to the fact that it is quite hard to portray in an image, but I’ll give it a shot:

Anyway, let’s take this mathematical representation of the sentence’s inner meaning and run it through the decoder model which will then give us the final result:
The really nice thing about this is that we can use the same intermediate representation of the sentence, but put it through another decoder model. Like this one, which will decode it into Spanish instead:
It gets even cooler when we try it with a decoder that is trained to decode into a bunch of pixel values, in other words, a picture of cute cats!
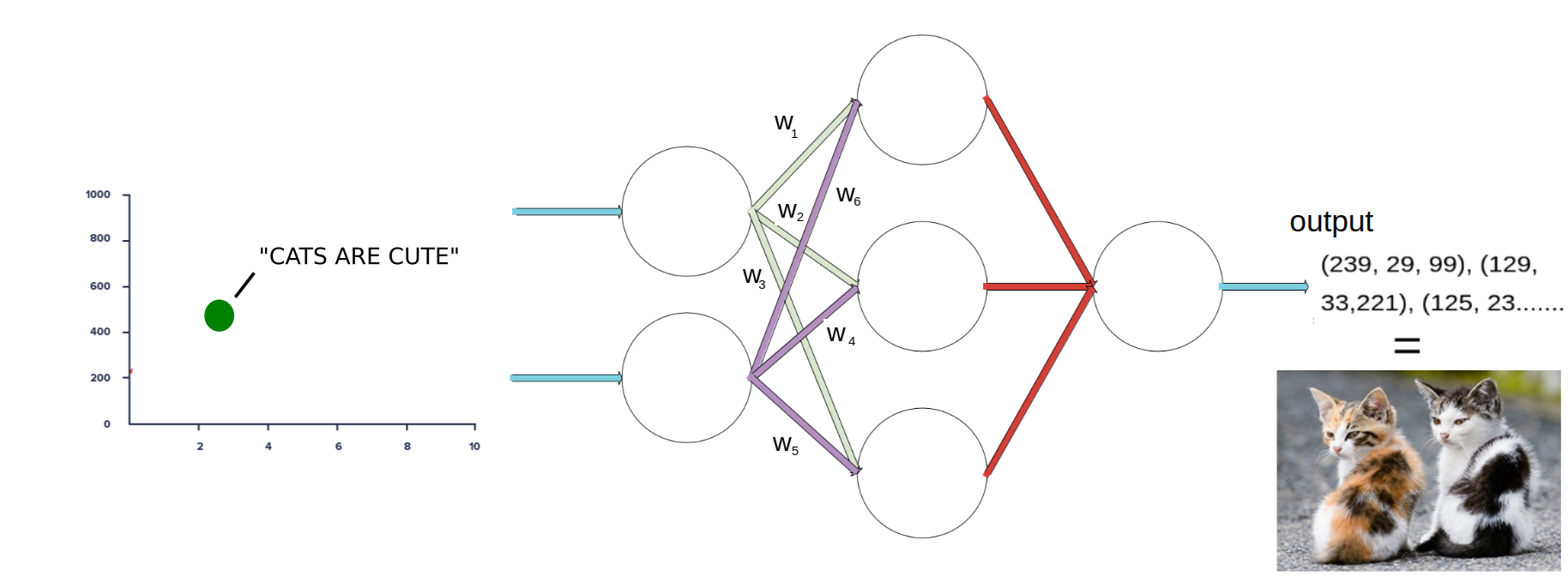
This is (kind of) how Open AI achieved their super impressive results with their DALL-E model that they recently came out with. You can read more about that on OpenAI’s DALL-E blog post.
DALL-E, GPT-3, Alphafold are all based on a type of Deep Learning model architecture that is called Transformers. Transformer-models were invented in 2017 and have accelerated the frequency of new AI breakthroughs massively since then! Transformers-models is also what we use to power our no code AI tool here at Labelf. Labelf even lets you train a transformer model without knowing anything about code! Or deep learning for that part. But we can’t count you to that crowd now that you’ve made it all the way here!
Per Näslund
CTO & Co-Founder



